Neuronale Netzwerke
Oktober 9, 2017
Aus dem CAS Disruptive Technologies mit Marcel Blattner berichtet Marcel Brändle.
Marcel Blattner führt uns ein in die Welt der Neuralen Netzwerken.
Alte welt = Programmieren vs. Neue Welt = Selbständig Regeln (Pattern) erarbeiten die sich weiterentwickeln und verbessern.
Zum Einstig schauen wir uns das Atari-Beispiel an. “Intelligente” Software lernt nicht auf die gleiche Art wie wir Menschen. Die Maschine lernt anhand eines “reward mechanismus”. Das heisst, bei jedem Durchlauf erhält die Maschine ein Feedback, ob ihr Handeln zum Erfolg oder eben zu keinem Erfolg geführt hat. Der Maschine wurde zu Beginn beigebracht, was als Erfolg und was als Misserfolg gilt. Anand dieser Feebacks passt die Maschine ihr Handeln an und wendet das Gelernte im neuen Anlauf an. Beim Atari-Beispiel hat die Software das Spiel noch nie zuvor gespielt. Ihr wurde z.B. nicht gesagt, “triff den Ball!” Einzig die Handlungsmöglichkeiten, der Spielraum und die “Rewards” waren bekannt.
Interessant ist, dass die Maschine anfänglich für uns Menschen völlig unkoordiniert spielt. Erst nach mehreren hundert Spieldurchläufen erreicht die Maschine ein vernünftiges Spielniveau. Doch schon nach 120 Minuten (mehrere tausend Durchläufe) hat die Software der Expertenlevel erreicht. Nach 240 Minuten (mehrere hunderttausend Durchläufe) geschieht etwas Bemerkenswertes: Die Maschine beginnt ihre Spielweise zu optimieren und spielt nun auf einem Niveau das für uns Menschen nicht erreichbar wäre.
Dieser Lernprozess hat hingegen eine Einschränkung. Die Verbesserung der Maschine nimmt zunehmend ab und stagniert irgendwann. Der Maschine fehlt die Intuition, um weitere Lernprozesse mit dem bereits Gelernten zu verknüpfen.
Touring Test
Alan Turing formulierte 1950 eine Idee, wie man feststellen könnte, ob ein Computer, also eine Maschine, ein dem Menschen gleichwertiges Denkvermögen hätte. Der Touring Test ist bestanden, wenn der Mensch nicht mehr unterscheiden kann ob ein Mensch oder die Maschine die Antwort/Reaktion gegeben hat.
Auf Domain-spezifische Beispiele bezogen, wurde der Touring Test schon bestanden. (Kunstexperten beurteilen Gemälde die von Computer produziert wurden)
Geschichte
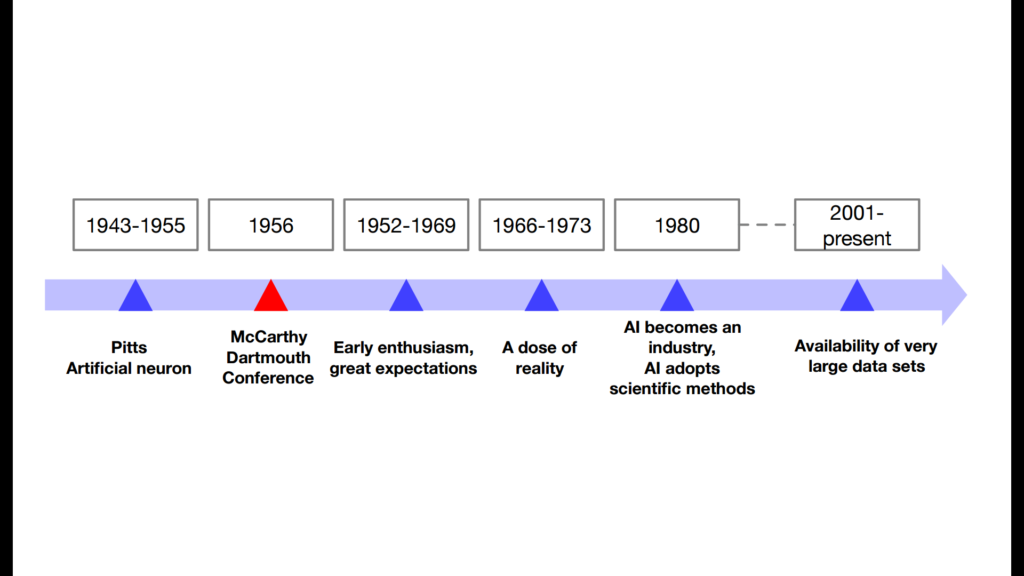
Die Anfänge der Theorien der künstlichen neuronalen Netze gehen auf Warren McCulloch und Walter Pitts im Jahr 1943 zurück. Sie zeigen an einem vereinfachten Modell eines neuronalen Netzes (McCulloch-Pitts-Zelle).
Am 13. Juli 1956 begann am Dartmouth College in Hanover (New Hampshire) eine 6-wöchige Konferenz unter dem Namen Dartmouth Summer Research Project on Artificial Intelligence. Seither gilt die Künstliche Intelligenz als ein akademisches Fachgebiet.
In der darauffolgenden Zeit bricht eine regelrechte Euphorie über KI aus. Die Wissenschaft verspricht Grosses und viel privates und öffentliches Geld wird in die Forschung investiert. Ab 1966 setzt dann die Ernüchterung ein, da die hohen Erwartungen nicht erfüllt werden konnten. Erst ab 1980 gewinnt die Forschung wieder an Schwung. Die Computertechnologie hat sich inzwischen so weit entwickelt, dass genügen Computing Power zu Verfügung steht, um die komplizierten Modelle auch zu rechnen. Seit 2001 erlebt das Forschungsfeld einen regelrechten Boom. Jetzt steht zusätzlich zur Computing Power auch eine umfangreiche Datenmenge zur Verfügung. KI wird immer präziser und immer mehr Anwendungsbereiche eröffnen sich.
Definition KI
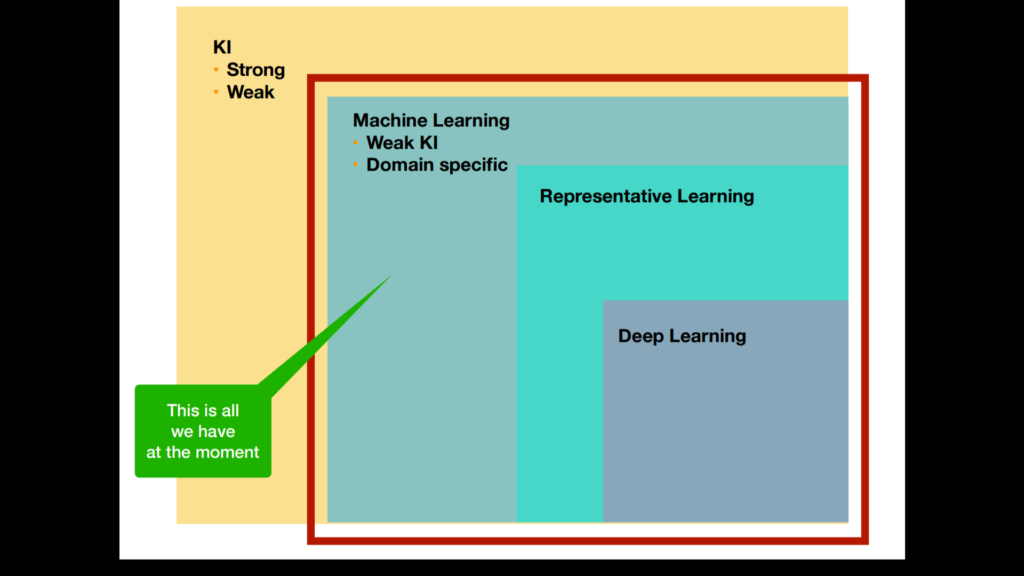
Die Ziele der starken KI sind nach Jahrzehnten der Forschung weiterhin visionär. Im Verständnis des Begriffs künstliche Intelligenz spiegelt sich oft die aus der Aufklärung stammende Vorstellung vom „Menschen als Maschine“ wider, dessen Nachahmung sich die sogenannte starke KI zum Ziel setzt: eine Intelligenz zu erschaffen, die das menschliche Denken mechanisieren soll, bzw. eine Maschine zu konstruieren und zu bauen, die intelligent reagiert oder sich eben wie ein Mensch verhält.
Im Gegensatz zur starken KI geht es der schwachen KI darum, konkrete Anwendungsprobleme des menschlichen Denkens zu meistern. Das menschliche Denken soll hier in Einzelbereichen unterstützt werden
Maschinelles Lernen ist grundsätzlich schwache KI und immer an ein bestimmtes Domain gebunden.
Unter Representative Learning versteht man, dass ein künstliches System aus Beispielen lernt. Das System kann diese nach Beendigung der Lernphase verallgemeinern. Das heißt, es werden nicht einfach die Beispiele auswendig gelernt, sondern es „erkennt“ Muster und Gesetzmäßigkeiten in den Lerndaten -> das sogenannte Pattern.
Deep Learning ist ein weiterer Schritt in die starke KI. Dabei werden neuronale Netze aus dem Gehirn künstlich auf dem Computer simuliert. Mehrere Lernmechanismen werden hintereinandergeschaltet. Output eines Lernprozesses ist Input für den nächsten Prozess
Die menschliche Überlegenheit liegt in der Kombination der Logik, Intuition und der Fähigkeit Konzepte zu transferieren. Wir sind der Maschine in der Logik unterlegen, können aber unsere Logik mit Intuition und noch viel komplexer, mit unabhängigen Konzepten verbinden. Das kann die Maschine nicht!
Konzeptuell hat die KI Forschung noch keine Vorschläge wie diese Kombination erreicht werden soll. Mit der klassischen Speicher-Prozessor Funktion kann dies bestimmt nicht erreicht werden.
Weitere Vorteile des menschlichen Gehirns.
Diese Analyse soll verdeutlichen, wie weit entfernt die KI noch von den menschlichen Hirnkapazitäten liegt.
Plastizität: Gehirn kann sich selbständig neu vernetzten wenn ein Teil ausfällt.
Parallelität: Dank der gigantischen Anzahl der Neuronen (ungef. 100 Mia), kann das Gehirn gleichzeitig mehrere Abläufe abwickeln.
20 Watt Maschine: Das Gehirn braucht unglaublich wenig Energie für die gesamte “Rechenleistung” 20 Watt vs. 9.8 Mega Watt beim Computer.
Veranschaulichung der Bilderkennung anhand des “Katzenbeispiels”
Wie ist ein Neurales Netzwerk aufgebaut?
Trainingsdaten – Testdaten
Labeling von Daten – zB Label “Katze”
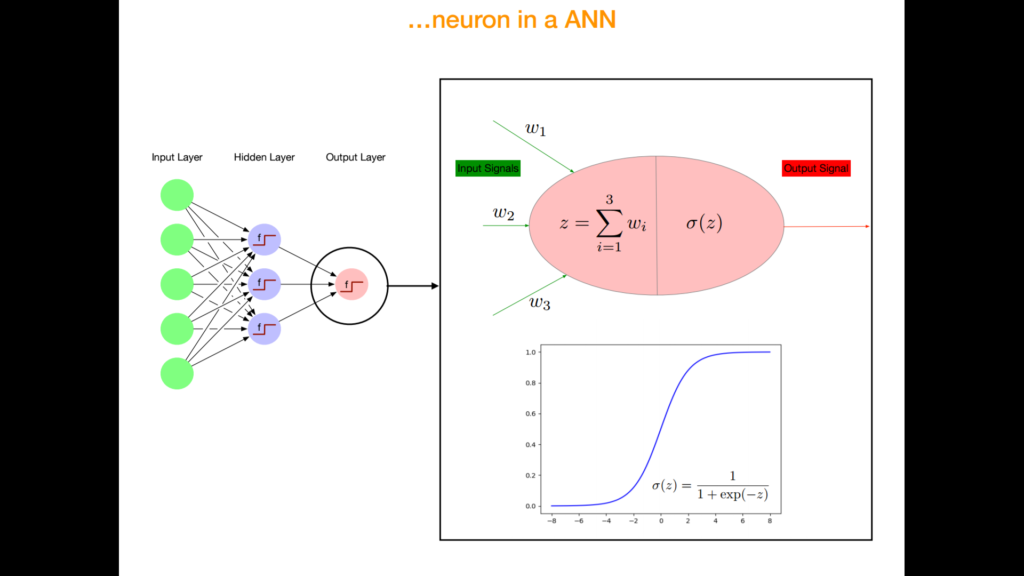
Input Layer
Jeder Pixel ist ein Wert. Zur Vereinfachung lassen wir Farben und Ausprägung des Pixels weg und nehmen an, dass ein Pixel entweder 1 (schwarz) oder 0 (weiss) sein kann.
Jeder Inputwert (Pixelwert) ist mit mehreren Second-Layer Knoten verbunden. Diese Verbindungen sind anfänglich zufällig angeordnet und optimieren sich im Prozess des “Lernens” nach dem Prinzip einer Gewichtung. Das heisst, die Maschine (Algorithmus) gibt den Verbindungen eine grössere Gewichtung, welche zu einem erfolgreichen Resultat führen. Die Verbindungen, welche keinen Beitrag zur Erfolgserzielung bringen, werden im fortschreitenden Lernprozess vernachlässigt und somit nicht weiter genutzt. Wie es genau zu dieser Auswahl kommt, weiss man nicht genau. Bezüglich der Funktionsweise der Gewichtung dieser verschiedenen Verbindungen tappt die Forschung noch im Dunkeln.
Die Second-Layer Knoten werden auch Neuronen genannt. Ihre Funktion gleicht deren von Neuronen in unserm Gehirn. Sie sind wiederum verbunden mit den Output-Layer Knoten, welche einen Wert ausspucken. Aus diesem Wert kann nun die Antwort abgeleitet werden “Katze” oder “Hund”.
Der Output Layer spiegelt die Werte, die von den Neuronen übermittelt werden auf eine Funktionskurve (siehe Bild). Da der Input-Wert nicht linear ist, wird so Zuordnungsbarkeit (Wahrscheinlichkeit Katze oder nicht) abgeleitet.
Y Achse: Zuordnungsbarkeit
0.5 = Eher Katze
0.8 = Sicher Katze
Der Algorithmus durchläuft diesen Input-Output Prozess viele tausend Male. Bei jedem Durchlauf werden die Verbindungen neu gewichtet. Nach dem Prinzip des Erfolgs oder Misserfolgs.
Der Algorithmus beginnt Linien, Kanten und Formen zu erkennen, welche das menschliche Auge (Gehirn) nicht so sehen (interpretieren) würde. Das heisst, ein Mensch analysiert und deutet ein Bild auf eine ganz andere Art und Weise. Die entstehenden Pattern, oder auch Labels genannt, machen für uns keinen Sinn. Die Maschine aber kann daraus Schlüsse ziehen. Kombiniert sie nun die vielen verschiedenen Pattern und Labels so kann die Maschine zum Schluss gelangen, dass das Bild eine Katze zeigt, oder eben einen Hund.
Die Maschine lernt also, indem sie die anfänglich zufällig angeordneten Verbindungen gewichtet. Der Trainings-Datensatz hilft ihr die wirksamen Verbindungen stärker zu gewichten und die unwirksamen Verbindungen abzuschalten. Dieser Trainingsdatensatz muss sehr umfangreich sein. Mehrere hunderttausende Bilder muss ein Programm trainieren, bevor sie mit einer hinreichenden Sicherheit eine Unterscheidung zwischen Hund und Katze erkennen kann.
Damit nicht ist genug. Marcel Blattner präsentiert uns die Bilderkennung auf eine sehr vereinfachte Art und Weise. In Realität ist der Mechanismus viel komplexer. Zu den Pixel-Werten kommt noch eine weitere, dritte Dimension hinzu.
Bilder sind nicht bloss 2D Abbildungen. Die Filter erstellen ein 3D Volumen des Bildes. Das Bild wird dadurch kleiner und kleiner, erhält dafür die Tiefendimension. Das Programm erstellt eine Vielzahl von dieses Filterkörper von kleinen Teilbereichen des Bildes und stellt sie in sogenannten “Pools” hintereinander.
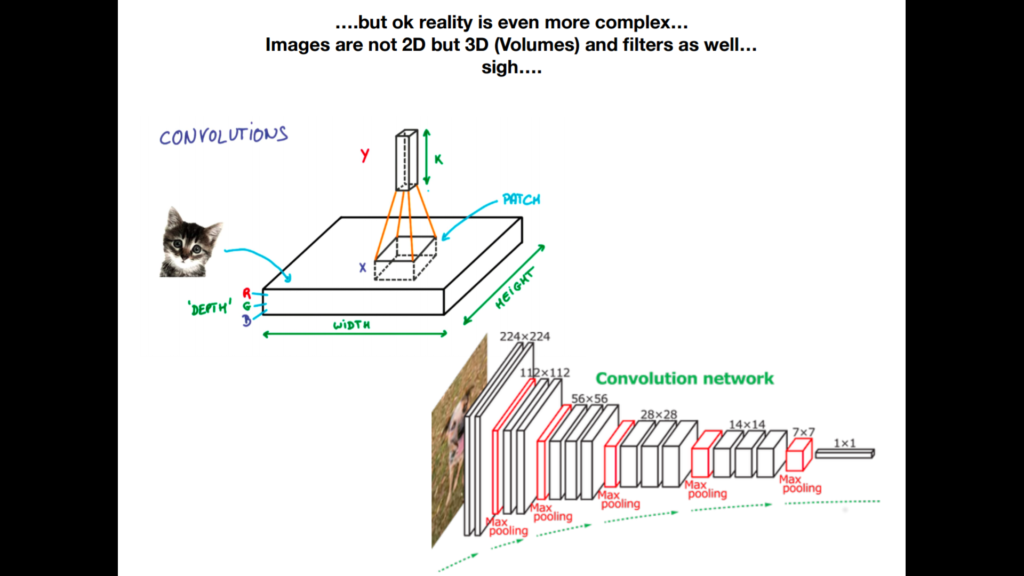
Wer jetzt noch findet: “..alles klar, easy, habe alles verstanden!”… hat mehr versanden, als bei der Prüfung verlangt wird. Marcel Plattner beruhigt die Klasse, dass wir über die Convolution keinen Vortrag an der Prüfung halten müssen.
Der Abschluss dieses Tages macht ein Ausblick in die Zukunft. Dabei stellt Marcel Blattner uns 10 Beispiele von zukünftigen Entwicklungen im Bereich der KI vor. Vom Cyborgs bis hin zum Brain Scanner bewegen wir uns irgendwo zwischen Science Fiction und Zukunftsvorhersage. “Beam me up, Scotty!”
Bleibe auf dem Laufenden über die neuesten Entwicklungen der digitalen Welt und informiere dich über aktuelle Neuigkeiten zu Studiengängen und Projekten.