Big Data in der Immobilien Industrie
Oktober 15, 2018
Die Referenten Simon Caspar (POM+) und Lukas Stöcklin (POM+) haben einen sehr spannenden und kurzweiligen Vormittag gestaltet. Das Modul “Life Cycle Data Management: Big or Small Data” vom 06.10.2018 im Studiengang CAS Digital Real Estate hat uns optimal in die Welt von Big Data und Data Science eingeführt. Es berichtet Martin Frei.
Big Data wird häufig als Sammelbegriff für digitale Technologien verwendet, die in technischer Hinsicht für eine neue Ära digitaler Kommunikation und Verarbeitung und in sozialer Hinsicht für einen gesellschaftlichen Umbruch verantwortlich gemacht werden (R. Reichert: Big Data: Analysen zum digitalen Wandel von Wissen, Macht und Ökonomie, 2014).
Big Data verfolgt das Ziel, Zusammenhänge aus grossen Datenmengen zu erkennen und entsprechend Struktur und Erkenntnis daraus zu ziehen. Die Resultate sollten danach in einfach lesbaren Cockpits ersichtlich werden. Hichert und Partner haben in Sachen Visualisierung von Charts und Resultaten wegweisende Guidelines erstellt. Folgendes Video gibt einen kurzen Einblick über die häufigsten Fehler in der Darstellung von Daten.
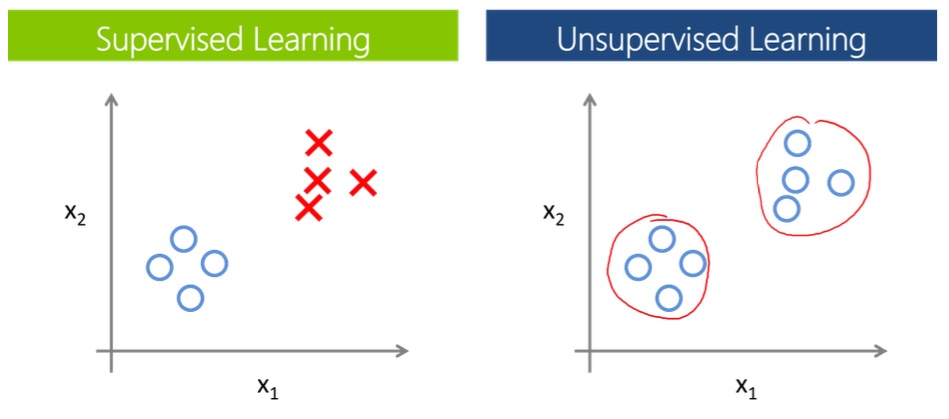
Die Dozenten haben anhand des “Titanic-Beispiels” aufgezeigt, wie aus mehrheitlich unstrukturierten Daten Erkenntnisse gewonnen werden können. Das Vorgehen einer Analyse wird meistens in folgende Steps unterteilt:
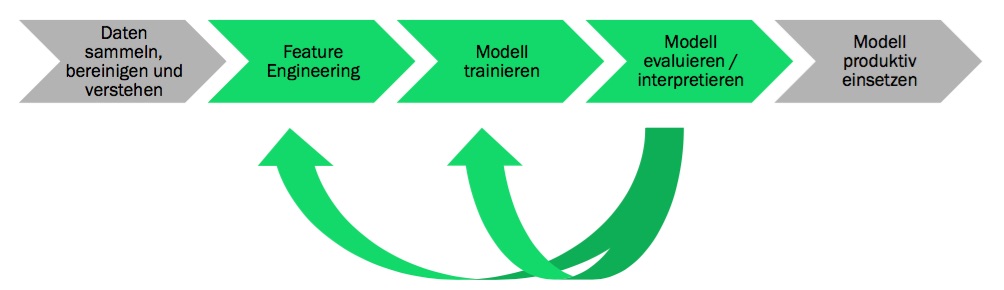
Nachdem Daten gesammelt und bereinigt und ein Datenmodell erstellt wurde, werden Testdatensätze verwendet, um das Modell zu trainieren. Mit den Methoden des Entscheidungsbaumverfahrens oder dem Random Forest Algorithmus wird das Modell trainiert.
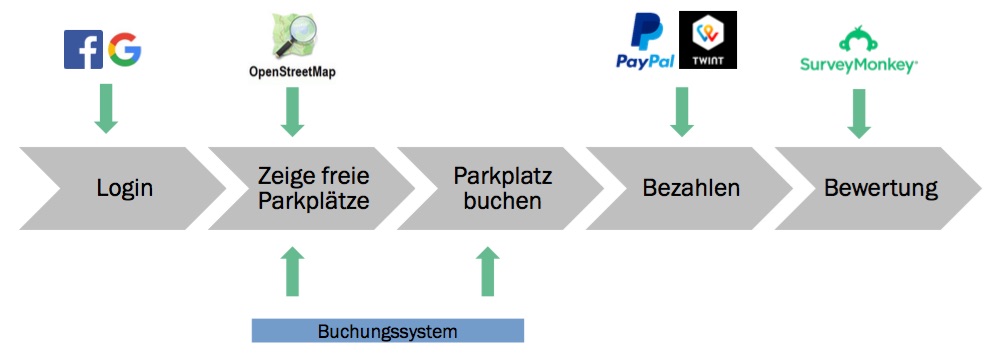
Um Daten aus vielen verschiedenen Systemen herausziehen zu können, sind Interfaces/Schnittstellen von grösster Wichtigkeit. Diese werden heutzutage meistens über Webservices genutzt. Hier hat sich SOA (Service Oriented Architecture) durchgesetzt. Diese Architektur ermöglicht es auch, eine Kette von verschiedenen Plattformen zu nutzen, um einen eigen Service anzubieten. Ein Beispiel ist eine Parkplatz App:
Folgende Fragen können nun aufgrund dieses Blogs beantwortet werden:
Bleibe auf dem Laufenden über die neuesten Entwicklungen der digitalen Welt und informiere dich über aktuelle Neuigkeiten zu Studiengängen und Projekten.