Hilfe! Ein AI Projekt
Juni 3, 2019
In diesem 1. Blog Beitrag des brandneuen CAS AI Management möchte ich kurz zusammenfassen was man in Bezug auf ein AI Projekt beachten sollte, damit es am Ende nicht zu einer Enttäuschung kommt.
Bei einem Machine Learning Projekt könnte der Projektablauf wie folgt aussehen:
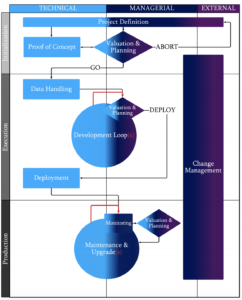
Die wahrscheinlich wichtigste Phase ist die ‘Projekt Definition’. Sie beschreibt, welches Vorhaben man erreichen möchte. Für diese Phase sollten etwa zwei Wochen aufgewendet werden.
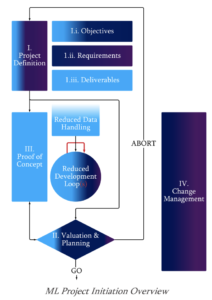
Es ist sehr wichtig, dass man festlegt welchen Bereich man mit KI verbessern oder unterstützen möchte. Die Themen sollte man gut abgrenzen. Eine Universallösung gibt es nicht.
Die Erwartungen an das Resultat müssen im vornherein klar sein. Welches sind die Zielwerte auf die man hinarbeitet? Wie viel spare ich, wenn der Algorithmus einen richtigen Treffer ausspuckt und was sind die Kosten die entstehen, wenn der Algorithmus eine Fehlentscheidung trifft. Auf der anderen Seite muss man sich auch überlegen wie viele positive Treffer man vom System erwartet und wie viele Fehlentscheidungen man verkraften kann. Diese Aufstellungen macht man in einer Classification’s Value Matrix bzw. einer Classification’s Confusion Matrix. Das sieht dann wie folgt aus:
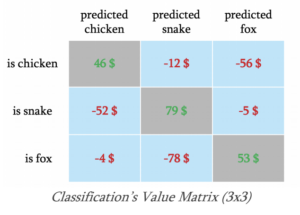
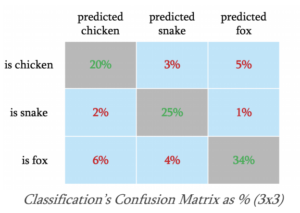
Im vorliegenden Beispiel werden Hühner, Schlangen und Füchse vom Modell erkannt. Wir gehen davon aus, dass 20% der Hühnerbilder auch als solche erkannt werden, bei 3% wird eine Schlange erkannt und bei 5% ein Fuchs. Wir erwarten, dass 28% der vom System zu erkennenden Tiere Hühner sind. In der Classification’s Value Matrix erfassen wir, dass uns ein als Fuchs erkanntes Huhn etwa 56$ kostet. So lässt sich nun abschätzen, ob die 5% als Fuchs erkannten Hühner wirtschaftlich verkraftbar sind oder ob wir das System weiter trainieren müssen, um die Erkennungsrate zu verbessern.
Ich gebe zu, dass das Beispiel zu Diskussionen anregen kann, da es doch eher abstrakt ist. Wer möchte schon, dass ein Modell Hühner, Schlangen oder Füchse zuordnen kann. Wir haben in der Klasse versucht das Ganze anhand von realeren Beispielen zu erarbeiten. Dabei haben wir ein Modell erarbeitet das mittels eines Bildes ein Schaden an einem Auto als Versicherungsfall klassifiziert oder nicht. Oder ein anderes Modell besprochen das mit Hilfe des Füllstandes eines Glascontainers den Zeitpunkt der Leerung bestimmt und somit die optimale Route für das Entsorgungsteam bestimmt. Dabei haben wir bemerkt, dass diese Phase nicht ganz einfach ist und zu einigen Diskussionen anregt. Deshalb lohnt es sich auch genügend Zeit dafür zu verwenden.
Ein weiterer, sehr wichtiger Punkt ist die Verantwortung in einem Projekt. Diese sollte nach Möglichkeit auf ein ganzes Team übertragen werden und weniger auf einzelnen Personen lasten. Die breitgefächerten Kompetenzen können kaum von einer Person abgedeckt werden. AI Projekte sind meistens ein kleiner Teil eines grösseren Projektes. Die folgenden Funktionen sind essentiell
Die unterschiedlichen Anforderungen sind gewaltig und die geforderten Skills sind sehr schwer zu finden. Es gibt verschiedene Optionen die Ressourcen für AI Projekte zu rekrutieren.
Die benötigte Kapazität intern aufbauen und die Mitarbeiter entsprechend ausbilden. Das lohnt sich hauptsächlich dann, wenn man grössere Projekte mit AI durchführt und die entsprechende Kompetenz aufbauen möchte.
—
Pros: Mehr Flexibilität; Innovationskräftiges MindSet ist intern
Cons: Management muss dahinter stehen; Die richtigen Leute sind schwer zu finden
Die Kapazität bei externen Firmen einkaufen. Es gibt einige Firmen die AI Consulting anbieten oder entwickelte Modelle unter Lizenz anbieten.
—
Pros: Weniger Probleme beim Recruiting; Schnellerer Know how Aufbau
Cons: Benötigtes Feature ist nicht als Produkt verfügbar; Schwierigkeiten die richtige Firma zu finden
Es gibt Firmen wie Swisscom, Google, Amazon oder Microsoft die gute AIaaS oder MLaaS anbieten. Das sind meistens Cloud Lösungen, existierende Datasets oder vorgefertigte Algorithmen.
—
Pros: Weniger Investitionskosten; Keine Daten Infrastruktur Probleme
Cons: Regulatoren (z.B. Ort der Datenspeicherung); Abhängigkeit zu einem Anbieter (Looked-In)
Es gibt Plattformen wie CrowdAI oder Kaggle auf denen man eine Aufgabe platzieren kann. Der Gewinner oder das Gewinner Team bekommt dann einen Preis und der Aufgabensteller das Modell
—
Pros: Verschiedene unterschiedliche Sichtweisen auf ein Problem; Firma wird sichtbar
Cons: Anforderungs-Änderungen können problematisch sein; Entwickelte Modelle sind zu komplex
Es ist wichtig, dass man bei einem AL Projekt genau weiss, welches Problem man lösen möchte und ob mit AI wirklich der gewünscht Nutzen erzielt werden kann. Auch sollte geklärt werden, ob die Aufgabe auch technisch umsetzbar ist. Dies wird vom Management oft vergessen. Wie bei allen Projekten sollte man auch bei AI Projekten Meilensteine und Resultate zeitlich festgelegt werden.
Es gibt die verschiedensten Anforderungen an die Daten, das Modell, Legal oder Integration, die man berücksichtigen muss. Die nachfolgende Liste ist nicht abschliessend, gibt aber einen Eindruck an was man alles denken sollte.
Die Lieferungen sollten den gestellten Anforderungen entsprechen. Bei einem PoC werden die wichtigsten Anforderungen geliefert. Danach werden die endgültigen Anforderungen ausgearbeitet. Eine grobe Idee des finalen Produktes sollte aber schon vorher bekannt sein.
Der Projektverlauf sollte konstant überwacht werden. Das dritt grösste Hindernis in einem AL Projekt ist der fehlende Management- und finanzielle Support. Ein rigoroses validieren schafft eine grössere Akzeptanz.
Bei der Planung von AI Projekten muss man darauf achten, dass die Beeinflussung des Menschen nicht zu einer Fehleinschätzung führt.
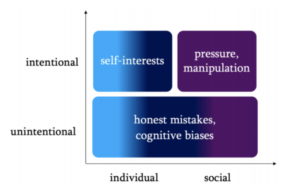
Um diese Beeinflussung zu mitigieren, muss man das politische Umfeld des Projektes kennen. Die Motive der internen und externen Akteure sollen transparent gemacht werden. z.B. Wer bezahlt die Evaluation oder was sind die Interessen der einzelnen Personen, die am Projekt beteiligt sind?
Den folgenden Punkten sollten eine starke Beachtung geschenkt werden.
Es sollte klar und unmissverständlich kommuniziert werden. Je nach Situation haben einzelne Wörter ein anderes Gewicht. Z.B ‘Wahrscheinlicher Regen in San Pedro de Atacama’ ist weniger wahrscheinlich als ‘Wahrscheinlicher Regen in Zürich’
Kürzlich erlebte Situationen können das Bild der Planung verzerren, da diese noch deutlich näher sind als Erfahrungen, die schon länger zurück liegen
Je nach Risikobereitschaft wird die Kosten/Nutzen Betrachtung beeinflusst. Eine Anreizkultur sollte eher die Qualität der Schätzung als das Erreichen des Ergebnisses fördern.
Bei einer Neuevaluierung muss man sicherstellen, dass diese Objektiv gemacht wird und nicht versucht wird die Vergangenheit zu bestätigen. Vor ‘Fail fast’ darf nicht zurückgeschreckt werden. Externe unabhängige Sichtweise könnte hier unterstützen.
Evaluationen basieren meist auf den anfänglich verfügbaren Informationen. Die Evaluationen sollten unbedingt den neuen Erkenntnissen angepasst werden. Neue Informationen dürfen auf keinen Fall ignoriert werden.
Bei der Entwicklung des Modells gibt es in der Regel mehrere Entwicklungszyklen. Der Aufwand der Zyklen wird einzeln für jeden Durchlauf geschätzt. In der Liste sind die einzelnen zu Schätzenden Bereiche und Tätigkeiten aufgeführt. Die Liste hat keinen Anspruch auf Vollständigkeit.
Die Szenario-Werte sollten so präzise wie möglich geschätzt werden. Hier zu erstellt man die oben erwähnten Classification’s Value Matrix und die Classification’s Confusion Matrix.
Wie bei anderen Projekten sollte auch bei AI Projekten frühzeitig mit Change Management begonnen werden. Es ist wichtig, dass jeder versteht wieso das Projekt aufgesetzt wurde. Dies schafft das Verständnis bei den Mitarbeitern und sie unterstützen eher das Vorhaben. Vor allem bei Zielen wie Kosten Reduktion sollte frühzeitig und vorsichtig kommuniziert werden.
Es gibt bereits viele Firmen die Services oder Tool im Bereich von AI anbieten. Nachfolgend eine Liste mit Anbietern in den verschiedenen Bereichen.

Schlechte Daten sind das grösste Hindernis für erfolgreiche AI Projekte! Bei vielen Firmen ist die Daten Menge eine grosse Herausforderung und somit eines der Hauptprobleme. Die zweit grösste Herausforderung ist die Daten Qualität gefolgt von der Verfügbarkeit und Verlässlichkeit der Daten.
In den meisten Fällen stellen die Daten eine grössere Herausforderung dar als zu Beginn noch angenommen! Ein strukturiertes Vorgehen könnte wie folgt aussehen

Research
Suche nach geeigneten Daten-Quellen und Daten
Beschaffung
Es gibt verschiedene Möglichkeiten Daten zu beschafften. z.B. Durch Scraping oder Daten-Einkauf
Speicher
Kosten der Datenspeicherung
Daten durchforsten
Daten anschauen und verstehen. Hier kann es sinnvoll sein die ursprünglichen Ziele ausser acht zulassen und andere Ideen zuzulassen.
Daten bearbeiten
Strukturieren, formatieren und organisieren der Daten, Bereinigung, Data Labeling. Für’s Labeling gibt es einige Firmen die Tools und Services anbieten. Bilder oder Sprachdateien werden angepasst
Daten überprüfen
Die Daten werden schon während des Daten durchforsten überprüft. Hier werden noch automatische Tests erstellt, so dass neue Daten schneller validiert werden können.
Features selektieren
Es werden einfache und verständliche Features empfohlen.
Versionierung
Die einzelnen Datensets werden versioniert. Das hilft bei Wiederverwendbarkeit z.B. bei Fehlersuche oder Testing
Pipelining
Die Datenflüsse werden automatisiert. Dies wird oft unterschätzt und kann sehr zeitintensiv sein.
Die Entwicklung ist das Herz jedes AI Projektes. Der Ablauf sieht wie folgt aus:
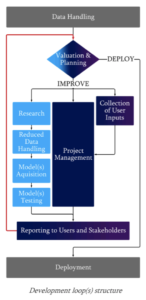
Es ist sehr wichtig, dass man laufend das Feedback der Benutzer einholt und sicherstellt, dass sich das Produkt in die richtige Richtung entwickelt.
Das Modell wird erst den Benutzern zugänglich gemacht, wenn ausreichend getestet wurde. Es ist auch wichtig, dass man das Environment kennt, in dem das Modell am Ende läuft. Die Performance für die Berechnungen, aber auch für die Daten-Pipeline und Interfaces muss geprüft werden und in einem akzeptablen Rahmen sein. Es ist auch wichtig, dass ein Rollback Plan besteht, für dem Fall das etwas schiefläuft.
In der Produktion sollte man sich über Monitoring und Maintenance Gedanken machen.
Zum Schluss noch ein paar Worte zum Team. Die einzelnen Team Mitglieder brauchen unterschiedliche Fähigkeiten. So macht es z.B. keinen Sinn alles Data Scientists einzustellen. Auf einen Data Scientist kommen etwa drei Data Engineers. Das erstellen und bearbeiten der Daten-Basis ist extrem Aufwendig.
Das Team sollte agile arbeiten können und möglichst kurze Entscheidungswege haben. Die ideale Team Grösse besteht aus 5 bis 6 Mitarbeitern. In jedem Team muss unbedingt Fachwissen vorhanden sein! Ohne geht es nicht. Nachfolgend drei Möglichkeiten wie ein Team aufgesetzt werden kann.
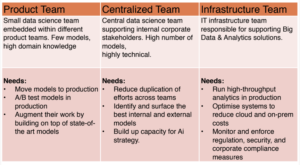
Es ist ebenfalls wichtig, dass die Rollen richtig besetzt sind. Ein Product Owner definiert das Produkt und nicht der Data Scientist, der erstellt das richtige Modell (technisch).
Der Start des ersten CAS AI Management war sehr spannend und für jedermann geeignet der sich für AI interessiert, jedoch nicht zu tief in die Welt der Algorithmen abtauchen möchte.
Bleibe auf dem Laufenden über die neuesten Entwicklungen der digitalen Welt und informiere dich über aktuelle Neuigkeiten zu Studiengängen und Projekten.