Stimm- und Spracherkennung in der Praxis
Dezember 19, 2019
Mal ehrlich, wer würde Alexa bitten einen Staubsauger zu bestellen oder Tickets für ein Konzert zu kaufen? So viele unterschiedliche Optionen die es vor einem Kauf eines Staubsaugers zu klären gilt wie Grösse, Farbe, Stärke, Staubauffang- und Saugtechnologie, Nutzung zu Hause oder im Auto. Kennt Alexa den bevorzugten Sitzplatz für das entsprechende Konzert und weiss sie wie viel man dafür bereit zu zahlen ist? Während des Entscheidungsprozesses könnte der Einsatz einer Sprachlösung (Stimm- und Spracherkennung) jedoch durchaus als Unterstützung dienen, beispielsweise bei der Online Recherche respektive der Produkte-Evaluation.
Es scheint einleuchtend, Vertrauen ist die Voraussetzung zur Nutzung der Sprachfunktion und dies nicht nur beim Online-Shopping. Einerseits schätzen Menschen den Fortschritt der Sprachsteuerung, auf der anderen Seite fürchten sie sich vor der Datensammlung durch permanentes unbewusstes Abhören.
Gabriela Kunath stellte ihre Studie ‚Voice Barometer 2019’ vor. Diese zeigt unter anderem die Akzeptanz und das Nutzungsverhalten von Sprachfunktionen. Die Veröffentlichung der Studie steht kurz bevor, weshalb aus diesem Vorlesungsteil keine Daten, Zahlen und Informationen aufgeführt sind.
„Die Erwartung ist, dass das System mich versteht, ohne dass ich schreibe“ meint Jürg Schleier, Country Manager DACH bei Spitch, einem Schweizer Unternehmen spezialisiert auf Sprach-Lösungen. Sprache ist natürlich und die meisten Menschen entwickeln sie im Kindesalter. Schreiben oder der Umgang mit einem Computer hingegen müssen wir erst erlernen. Dadurch ergibt sich ein Wettbewerbsvorteil für die Sprachsteuerung.
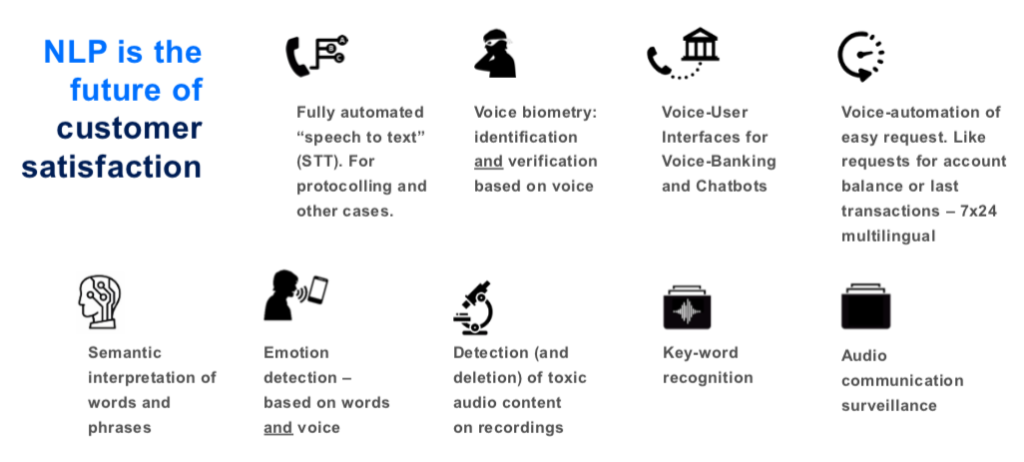
Erkennen von Gesprochenem und Umwandeln von Sprache in Text. Es findet eine Protokollierung des Gesprochenen statt.
Eine Stimme erkennen und zuordnen. Die Stimme gehört zur Person XY ähnlich dem Fingerabdruck.
Anstatt Eintippen in den Chatbot mittels Sprache kommunizieren.
Günstige Alternative zu einem Callcentermitarbeiter. Die Beantwortung von Standardanfragen wie durch Maschinen (7x24h und mehrsprachig). Anfragen wie Kontostand, letzte Buchungen oder Kreditkarte sperren.
Semantische Interpretation von ähnlichen Wörtern. Beispiel: Ein Kunde ruft an und sagt: „Ich kann keine E-Mail mehr schicken“. Keine E-Mail mehr senden wird interpretiert als: „Ich habe ein Problem und benötige Support“ und dies ohne dass der Kunde die Wörter ‚Problem’ oder ‚Support’ benutzt.
Automatische Erkennung der Stimmung des Anrufers mittels Sentiment-Analyse. Ist der Kunde zufrieden oder unzufrieden. Dies geschieht durch Analyse der durch den Kunden benutzten Wörter. Dabei werden Wörter wie fantastisch, toll oder grossartig als positiver, mühsam, schlecht, ungenügend als negativer Sentiment erkannt. Auch Emotionen wie zum Beispiel traurig, aufgestellt oder genervt werden aus der Stimme gelesen. Die Trefferquote von ‚emotion detection’, alleine angewendet, liegt bei etwa 60%, jedoch in Kombination mit Sentiment-Analyse deutlich höher. Ebenfalls aus der Stimme herausgehört werden können Früherkennungssignale für bestimmte Krankheiten wie Alzheimer und Parkinson.
Unternehmen wollen gewisse Informationen ihrer Kunden nicht auf Band aufnehmen oder speichern. Spricht der Kunde beim Anruf bei der Kreditkartenfirma die Kartennummer und den Pin aus, möchte das Unternehmen diese Information nicht speichern. Zuerst die vertraulichen Informationen löschen, danach die Aufnahme speichern.
Herausfiltern von bestimmten Schlüsselwörtern, um Daten über ein bestimmtes Thema zu suchen und zusammen zu tragen. Möglich ist ein Einsatz beim Regulator FINMA, um Anfragen rasch- und bestmöglich erfüllen zu können. Bei Banken werden Telefongespräche teilweise aufgenommen. So könnte eine FINMA Anfrage lauten: Wer hat zwischen Donnerstag 8.00 und Montag 17.00 mit Pierin Vincenz über Investnet gesprochen? So werden die Wörter Pierin Vincenz und Investnet als Schlüsselwörter eingegeben um an die entsprechenden Informationen zu gelangen.
Die Sprachüberwachung in einem Land wie der Schweiz ist herausfordernd aufgrund des Schweizerdeutsch und all der Dialekte, welche keine Regeln kennen. Für das Wort „Öpfelbütschgi“, oder auf Hochdeutsch „Apfelkerngehäuse“, gibt es etwa 15 unterschiedliche Ausdrucksweisen. Alle unterschiedlichen Ausdrücke korrekt zu erkennen ist eher unwahrscheinlich oder brauch sehr viel manuelle Nachbesserung. Für Sprachen wie Englisch oder Hochdeutsch kann der Computer die Sprache mittels einlesen von Sprachführern und Lexika erlernen und erkennen. Durch ergänzende Informationen Grammatikregeln und Silbenerkennung erhält man bereits eine relativ gute Spracherkennung.
Spitch hat ein Proof of Concept (POC) bei SRF Meteo durchgeführt. Die automatische Simultanübersetzung vom gesprochenen Schweizerdeutsch aus dem SRF Meteo in hochdeutsche Untertitel ergab eine Erkennungsrate von etwa 75%.
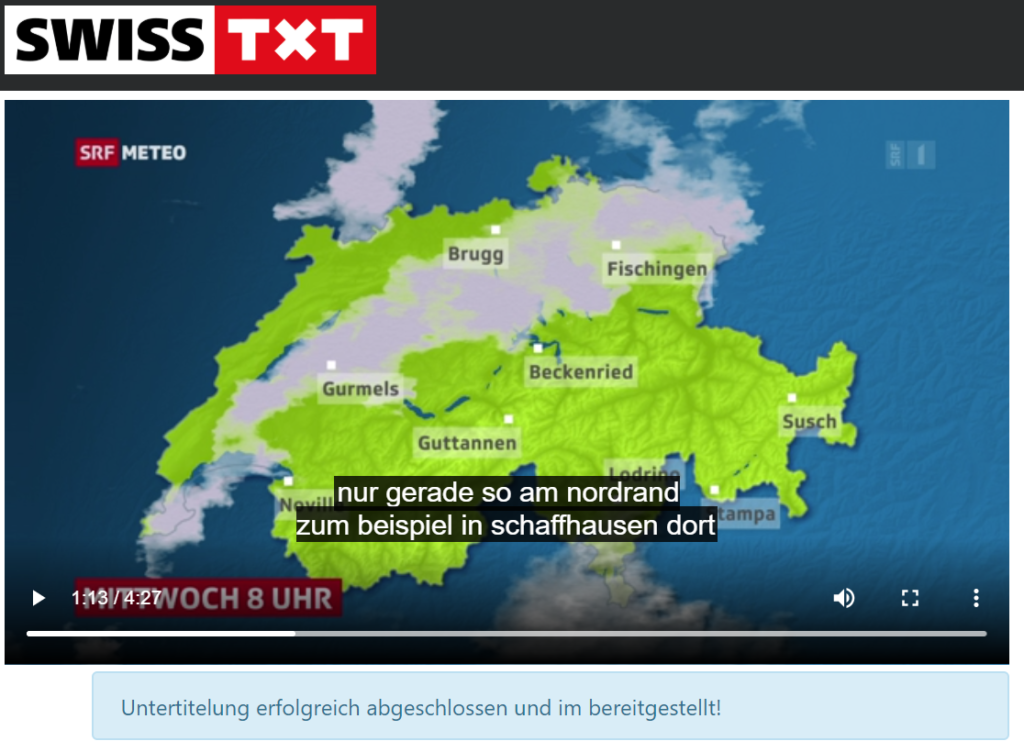
Stimm- und Spracherkennung PoC Spitch
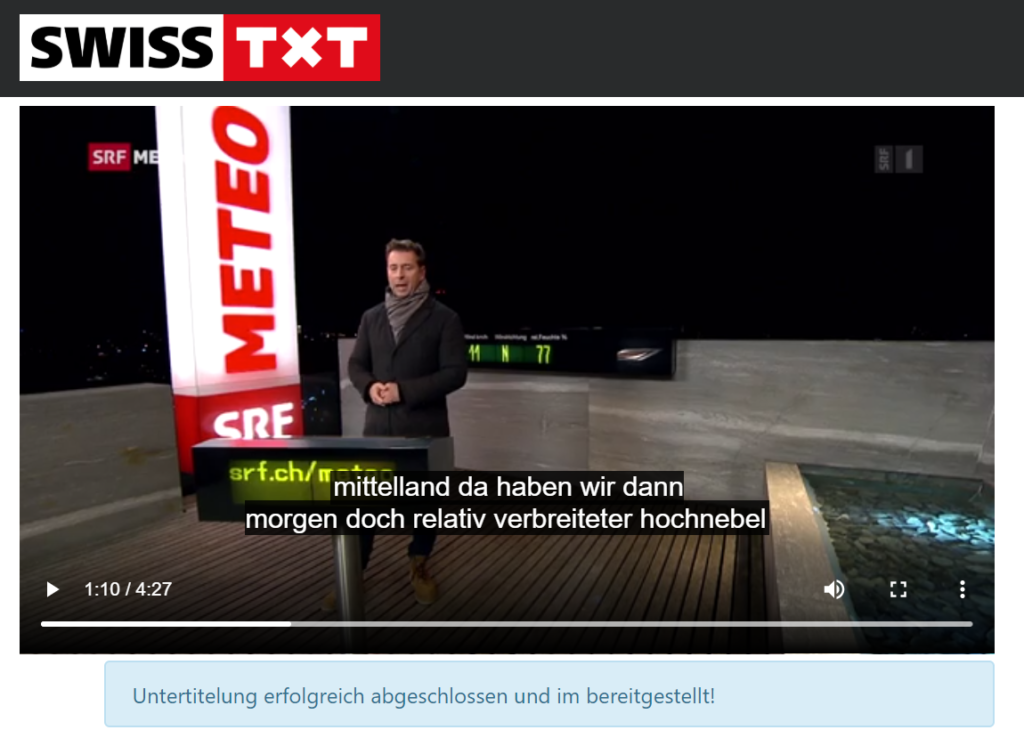
Stimm- und Spracherkennung PoC Spitch
Die akademische Messformel für die Erkennungsrate ist ‚word error rate’, das heisst wie viele Wörter in einem Text sind falsch. Je mehr Referenzdaten vorhanden sind desto grösser wird die Erkennungsrate, angereichert mit Gross- und Kleinschreibung und Satzzeigen könnte die Erkennungsrate mit wenig Aufwand auf 90% gesteigert werden. Die menschliche ‚word error rate’ liegt etwa bei 95%.
Mögliche weitere Einsatzmöglichkeit für Spracherkennung sind im Umfeld von:
Gaming: Sprachsteuerung anstatt Eingabe über eine Hardware. Problematik ist die Sprachenvielfalt welche bedient werden müsste, analog zu Sprachlösungen für das Auto.
Kinder & Spielzeuge: Beispielsweise eine Puppe welche Aufgaben stellt die beantwortet werden müssen und somit zum spielerischen Lernen anregt. An Referenzdaten von Kindern zu kommen ist juristisch äusserst schwierig.
Ältere Menschen: Bestellen von medizinischem Equipment via Spracheingabe. Unterhaltungsangebot bei Mangel an Pflegepersonal (Roboter), wachsender Markt, im Alter entwickelt sich eine spezifische Sprache (langsam, undeutlich)
Militär / Flugüberwachung / Spital: Mit Spracherkennung den Stresslevel messen. Mit den Nebengeräuschen eine Herausforderung.
Küche: Eher schwieriges Umfeld durch Lärmkulisse erschwerte Spracherkennung und gute Filter für Entfernen der Nebengeräusche notwendig

Bestehende Gespräche werden als Referenzdaten verwendet. Je mehr Referenzdaten, desto besser die Statistik wie oft kommt welche Kombination in welcher Situation vor. Dadurch erhöht sich die Wahrscheinlihckeit die richtige Wahl zu treffen.
Analyse der Referenzdaten wie mit Wort und Satzstellungen Sätzen gebildet werden
Welche Wörter werden in welcher Wortfolge zu Sätzen gebildet?
Wie setzten sich Wörter zu Sätzen zusammen?
Wenn aus einem Satz mit 5 Wörtern eines der mittleren Wörter entfernt wird, wird kombiniert, welches Wort oder welche Wörter passen würden, um dem Satz eine sinnvolle Bedeutung zu geben.
Analyse der Referenzdaten wie setzen sich Wörter aus einzelnen Silben zusammen
Aus einem Wort mit 5 Silben wird eine Silbe entfernt. Hier kann es natürlich unterschiedliche Silbenkombinationen geben. Die Silbenkombination ergibt 3 unterschiedliche Wörter. Die Frage ist aber, welches Wort ergibt im Satz einen Sinn?
Die statistischen Werte zeigen wie oft eine Silbenkombination in den Referenzdaten vorkommt. Man wählt die Kombinationen, welche bei mehr als 90% sind und prüft dann ob diese im Wort und in der Satzstellung Sinn ergibt.
Akustischer Filter
Unser Gehirn filtert Nebengeräusche wie Klopfen während eines Gesprächs automatisch heraus. Es unterscheidet was gesprochener Text ist und was nicht dazu gehört. Das funktioniert bei Sprachlösungen genauso, sie ordnen Text dem Gesprochenen zu und was nicht dazu gehört ist als Nebengeräusch identifiziert.
Damit Sprachlösungen erfolgreich sind, müssen ein paar Erfolgsfaktoren erfüllt sein:
Damit eine grosse Menge an Referenzdaten zur Verfügung steht, könnten Daten auch eingekauft oder über Crowdfunding erworben werden. Hier gilt es jedoch zu beachten, dass unter Umständen ein grosser Teil der Daten unbrauchbar sein könnte (z.B. rassistisch, sexistisch) und mit viel Aufwand qualitätsgeprüft werden muss – das lohnt sich in der Regel nicht. Daten welche in grossen Mengen vom Fernsehen oder Radio zur Verfügung gestellt werden, wären sehr nützlich, jedoch nicht zur Weitergabe freigegeben. Dies weil zwar das Fernsehen oder Radio die Einwilligung des Gesprächspartners für die Speicherung der Aufnahmen hat, jedoch keine explizite Einwilligung zur Weitergabe dieser.
Beziehung und Vertrauen aufbauen passiert über Menschen und den persönlichen Kontakt. Da die Ressource Mensch jedoch teuer ist, will man diese optimal einsetzten und nicht für Standard oder Routine Aufgaben oder Anfragen verschwenden. Maschinen können solche Aufgaben kostengünstig erledigen, wie beispielsweise bei Banken die Abfrage des Kontostands, der Zinsen für Hypotheken oder die aktuelle Währungskurse und die Aktienpreise.
Bei nur wenig Anrufen rechnet sich die Einführung von Stimm-und Spracherkennung nicht. Ein Beispiel für eine Bank mit im Schnitt 800 Anrufe worum sich rund 30-40 Mitarbeiter kümmern. Bei einer Einsparung von 10% rechnet sich der Business Case nicht.
Ein anderes Finanzunternehmen mit 1.8 Millionen Anrufen pro Tag und 300 Mitarbeitern für deren Entgegennahme rechnet sich der Business Case bei einer Einsparung von 10%.
Ein Unternehmen hat eine Analyse der Anrufe gemacht um zu sehen warum die Kunden anrufen. Es wurde festgestellt, dass es sich bei 50% der Anrufe um Standardfragen handelt wie z.B. Ich wohne in Zürich, kann ich in Aarau die Nummernschilder zurückbringen; Ich muss mein Auto vorführen, muss ich persönlich vorbei kommen oder kann dies jemand anderes für mich übernehmen, etc. Das Unternehmen entscheidet aufgrund des verfügbaren Personals, ob das System oder ein Mitarbeitender den Anruf entgegennimmt. Am Abend wird das System per Knopfdruck eingeschaltet. Das System beantwortet ausserhalb der Öffnungszeiten Standardanfragen automatisch. Bei komplexen Fragen verweist es den Kunden auf den nächsten Tag entsprechend der Büroöffnungszeit.
Ein anderes Unternehmen versendet jeweils im November etwa 1.5 Millionen Rechnungen. Aufgrund der grossen Anzahl von Rückfragen bezüglich der Rechnung, wünscht sich das Unternehmen eine Sprachlösung, welche sich ausschliesslich diesem Thema annimmt und Fragen rund um die Rechnung selbständig und automatisch beantwortet. Bei den Anfragen handelt es sich um Standardfragen wie z.B. “Ich habe kein Auto mehr; Mein Auto ist neu; Kann ich die Rechnung in zwei Raten bezahlen?”, etc.

Stimm- und Spracherkennung – der Stimmabdruck
Damit ein Stimmabdruck erstellt werden kann, wird mindestens eine Minute gesprochener Text benötigt. Danach wird dieser Text analysiert und rund 1000 Faktoren, wie Höhen und Tiefen und die Kadenz der Stimme, bestimmen wie sich die Stimme zusammensetzt. Nachdem der Stimmabdruck erstellt wurde wird der gesprochene Text gelöscht. Aufgrund des Stimmabdrucks kann nicht mehr nachvollzogen werden was gesagt wurde oder wer gesprochen hat. Ein Stimmabdruck ist eine sehr genaue Beschreibung der Stimme. Aus dieser Beschreibung kann die Stimme nicht wiederhergestellt werden.
Nach 10 Sekunden gesprochenem Text erfolgt die Erkennung der Stimme des Anrufers, welche zugewiesern oder abgelehnt wird.
Wie sicher ist Voice Biometry? Die Schärfe oder Toleranz der Stimmerkennung kann unterschiedlich eingestellt werden was je nach Einstellung zu einer hohen Rate an false acceptance oder false rejection führen kann.
False acceptance: Jemand, der keinen Zugang haben müsste, wurde zu unrecht angenommen
False rejection: Jemand, der Zugang haben müsste, wurde zu unrecht zurückgewiesen
Eine typische Anwendung für den Zutritt mittels Stimmerkennung ist beispielsweise ein Kreditkarteninstitut. Dort könnte die Stimmabdruck anstelle der drei Fragen dienen („Wann wurde die Kreditkarte das letzte Mal benutzt, für welchen Betrag, gibt es eine Vollmacht für eine weitere Person?“).
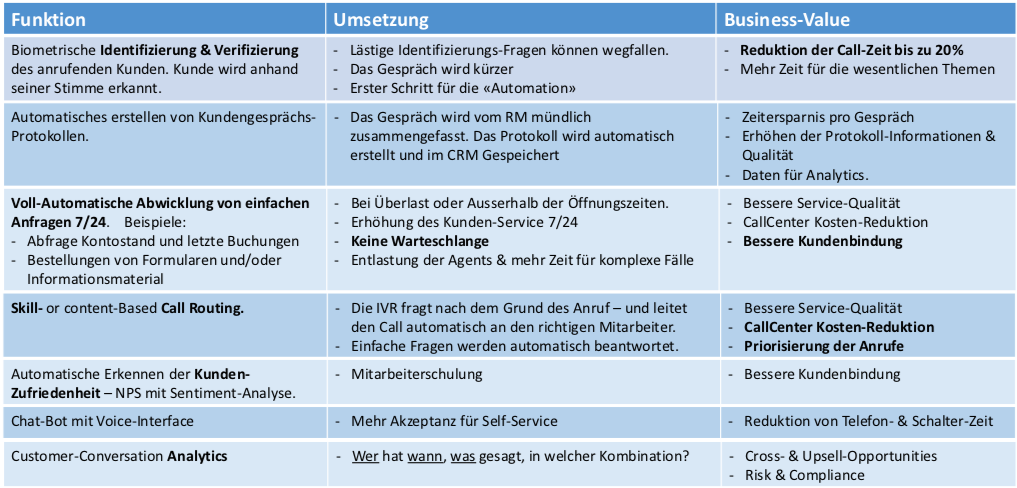
Ein Kunde ist in den Ferien und hat seine Kreditkarte verloren. Er wählt die Notfallnummer des Kreditkartenherausgebers. Dort meldet sich ein System „Guten Tag bei no-name, Sie sprechen mit dem automatischen System bitte schildern sie Ihr Anliegen“.
Der Kunde: „Mein Name ist Hans Muster, ich bin in Südafrika in den Ferien und habe meine Mastercard verloren. Ich möchte diese gerne sperren lassen“.
Das Anliegen des Kunden wird direkt mittels speech to text protokolliert und aufgrund von bestimmten Schlüsselworten wird der Kunde im aktuellen Fall direkt dem Agent für ‚Kartensperrung International’ zugewiesen. Der erhält ein Popup angezeigt mit dem Problem des Kunden woraufhin er einen Knopf drückt mit der Mitteilung „Guten Tag Herr Muster, ich habe ihr Problem verstanden und es ist in 5 Sekunden gelöst“.
Der Vorteil ist, dass der Kunde direkt zu einem Mitarbeiter kommt, der auf das entsprechende Thema spezialisiert ist und so das Anliegen effizient erledigt und wird nicht x-mal weiterverbunden. Die Gesprächszeiten bei Kreditkartenherausgeber haben sich mit der Einführung dieses Systems um 20% reduziert.
Für die Einführung wurden 30’000 reelle Kundengespräche aufgenommen und teilweise manuell Kategorien zugeordnet (Schlüsselworte).
Die Trefferquote (Intent-Erkennung) liegt bei 91% und die word error rate bei 75%, man versteht doch schon sehr gut um was es geht und die Fehler sind primär grammatikalischer Art, „der die das“ ist teilweise falsch, es heisst KartE anstatt KartEN, also keine schwerwiegende Fehler etc.
Was funktioniert gut für Sprachlösungen, was nicht?
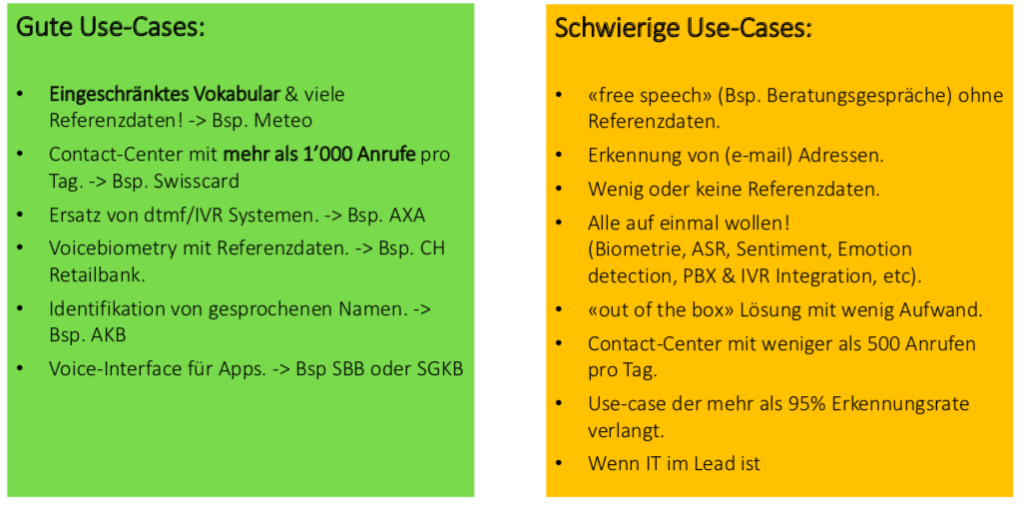
Welche Voraussetzungen müssen vom Datenschutz in der Schweiz und in der EU erfüllt sein, wenn man eine Voice-Lösung anbieten möchte?
1: https://www.edoeb.admin.ch/edoeb/de/home/datenschutz/technologien/biometrie/erlaeuterungen-zu-stimmerkennungsverfahren.html
2 Seite 17: https://www.capgemini.com/wp-content/uploads/2018/01/dti-conversational-commerce.pdf
Kundenbedenken: Willige ich beispielsweise auf dem iPhone ein Siri zu nutzen, stimme ich zu, dass mein Smartphone alles aufzeichnet und an Apple sendet. Das heisst Apple weiss über alles Bescheid wo Siri eingebunden wird, wie beispielsweise was ich mittels Siri im Internet suche, wen ich anrufe, wem ich welche Mitteilung sende, mein Bewegungsprofil und vieles mehr.
Was spricht für Spitch als Startup, wenn man mit Siri oder Google eine viel grössere Menge an Referenzdaten hat?
Abschliessend kann festgestellt werden, dass Stimm- und Spracherkennung auf jeden Fall interessierte Abnehmer am Markt hat!
Was sind Stimm- und Spracherkennung?

Literaturempfehlung Gabriela Kunath:

Bleibe auf dem Laufenden über die neuesten Entwicklungen der digitalen Welt und informiere dich über aktuelle Neuigkeiten zu Studiengängen und Projekten.